So don't be afraid of AI in your daily job as Awesome Developer / Admin / Adminloper.
A new revolution has come in the CRM world and Salesforce leads it as usual.
Einstein is AI brought to our beloved CRM platform, in may ways: enriches your sales decisions, marketing strategies, smartifies your communities and your social behavior.
I know what you are thinking, how can a humble Salesforce developer empower Artificial Intelligence?
Again, afraid be not!
Salesforce conveys a set of APIs for image recognition or text analysis, so you can integrate the power of AI into your application, whether inside Salesforce or not.
What can you do with Einstein APIs?
At the time of writing, you can:
- Classify images
- Detect number, size and position of objects inside images
- Classify sentiment in text
- Categorize unstructured text into user-defined labels
Read the complete documentation at metamind.readme.io.
In this post I'll cover an example of how to classify images using Einstein Vision.
Use Case
Can you guess a business use case for this API?
A particulas piece of my fridge just broke down and it is difficult to explain by words which part should be replaced.
Just take a picture of the part and submit to the Einstein Vision engine (properly trained): the backoffice user may now be able to tell the "replacemente department" which part should be sent to the customer.
Another example, my hoven is not working and I don't remember the model: take a pic, send to Einstein engine, the system can guess the model and execute the proper actions.
In our example we'll just try to classify apples, not a cool business use case but it effectively shows how the library works.
First configurations
First thing to do is registering for the free Einstein Vision tier.
Go to https://api.einstein.ai/signup, register with your Developer ORG edition (use the Salesforce flow) and then download and save the provided key in the einstein_platform.pem file.
Go to your ORG and create a new Static Resource for this certificate and call it Einstein_Platform: this will be used to generate a JWT OAuth token every time it is needed.
Now create a new Remote Site Setting adding the https://api.metamind.io endpoint (this is the Einstein Vision API endpoint).
Now you are ready to use the provided package.
Before starting you should install the following Apex packages into your ORG (they are open source Einstein Vision wrappers):
Download and install into your ORG the following code from REPO: it's just 2 pages and 2 classes.
Before starting be sure to change your Einstein APi email address in the EinsteinVisionDemoController:
public static String getAccessToken(){
String keyContents = [Select Body From StaticResource Where Name = 'Einstein_Platform' limit 1].Body.toString();
keyContents = keyContents.replace('-----BEGIN RSA PRIVATE KEY-----', '');
keyContents = keyContents.replace('-----END RSA PRIVATE KEY-----', '');
keyContents = keyContents.replace('\n', '');
// Get a new token
JWT jwt = new JWT('RS256');
jwt.pkcs8 = keyContents;
jwt.iss = 'developer.force.com';
jwt.sub = 'your@email.here';
jwt.aud = 'https://api.metamind.io/v1/oauth2/token';
jwt.exp = '3600';
String access_token = JWTBearerFlow.getAccessToken('https://api.metamind.io/v1/oauth2/token', jwt);
return access_token;
}
Configure the Dataset
This repo has a configuration page (for model training) and a prediction page (see a live demo here ).
Let's open the administration page named EinsteinVisionDemoAdmin.
In the Dataset URL input copy the following dataset URL: https://raw.githubusercontent.com/enreeco/sf-einstein-vision-prediction-demo/master/dataset/mele.zip.
This ZIP file contains 6 folders: each folder represent a kind of apple (the folder name is the corresponding name) and it contains a list of 40/50 images of that kind of apple (I'm not an expert of apples, so some pictures may not be correct!).
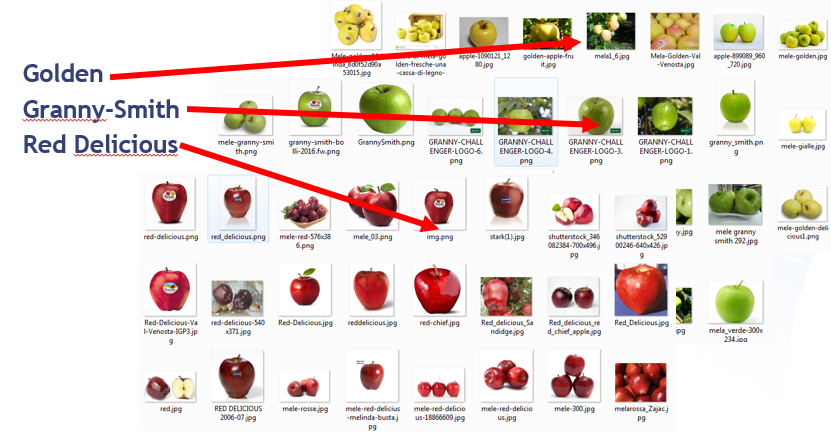
Now press the Create Model Async button: there are 2 kinds of API for this porporuse, one is sync (and accepts zip files of up to 5 MB) and the other one is async (and accepts size of more than 5 MB).
This means that in this example we'll be using only the async API: the request is taken in charge:
DATASET:
{
"updatedAt" : "2017-07-11T14:17:33.000Z",
"totalLabels" : null,
"totalExamples" : 0,
"statusMsg" : "UPLOADING",
"name" : "mele",
"labelSummary" : {
"labels" : [ ]
},
"id" : 1006545,
"createdAt" : "2017-07-11T14:17:33.000Z",
"available" : false
}
Now you can press the button labelled Get All Datasets and Models to watch the upload operation complete:
Datasets: 1
{
"updatedAt" : "2017-07-11T14:17:37.000Z",
"totalLabels" : 6,
"totalExamples" : 266,
"statusMsg" : "SUCCEEDED",
"name" : "mele",
"labelSummary" : {
"labels" : [ {
"numExamples" : 38,
"name" : "red_delicious",
"id" : 52011,
"datasetId" : 1006545
}, {
"numExamples" : 44,
"name" : "granny_smith",
"id" : 52012,
"datasetId" : 1006545
}, {
"numExamples" : 45,
"name" : "royal_gala",
"id" : 52013,
"datasetId" : 1006545
}, {
"numExamples" : 42,
"name" : "golden",
"id" : 52014,
"datasetId" : 1006545
}, {
"numExamples" : 53,
"name" : "renetta",
"id" : 52015,
"datasetId" : 1006545
}, {
"numExamples" : 44,
"name" : "fuji",
"id" : 52016,
"datasetId" : 1006545
} ]
},
"id" : 1006545,
"createdAt" : "2017-07-11T14:17:33.000Z",
"available" : true
}
Now we can train our model by copying the dataset id into the Dataset ID input box and pressing the Train Model button: Einstein analyzes the images with its deep learning algorithm to allow prediction.
MODEL:
{
"updatedAt" : "2017-07-11T14:21:05.000Z",
"trainStats" : null,
"trainParams" : null,
"status" : "QUEUED",
"queuePosition" : 1,
"progress" : 0.0,
"name" : "My Model 2017-07-11 00:00:00",
"modelType" : "image",
"modelId" : "UOHHRLYEH2NGBPRAS64JQLPCNI",
"learningRate" : 0.01,
"failureMsg" : null,
"epochs" : 3,
"datasetVersionId" : 0,
"datasetId" : 1006545,
"createdAt" : "2017-07-11T14:21:05.000Z"
}
The process is asynchronous and takes some time to complete (it depends on the parameters passed to the train API, see code).
Press the Get All Datasets and Models button to see the process ending:
Datasets: 1
{
"updatedAt" : "2017-07-11T14:17:37.000Z",
"totalLabels" : 6,
"totalExamples" : 266,
"statusMsg" : "SUCCEEDED",
"name" : "mele",
"labelSummary" : {
"labels" : [ {
"numExamples" : 38,
"name" : "red_delicious",
"id" : 52011,
"datasetId" : 1006545
}, {
"numExamples" : 44,
"name" : "granny_smith",
"id" : 52012,
"datasetId" : 1006545
}, {
"numExamples" : 45,
"name" : "royal_gala",
"id" : 52013,
"datasetId" : 1006545
}, {
"numExamples" : 42,
"name" : "golden",
"id" : 52014,
"datasetId" : 1006545
}, {
"numExamples" : 53,
"name" : "renetta",
"id" : 52015,
"datasetId" : 1006545
}, {
"numExamples" : 44,
"name" : "fuji",
"id" : 52016,
"datasetId" : 1006545
} ]
},
"id" : 1006545,
"createdAt" : "2017-07-11T14:17:33.000Z",
"available" : true
}
{
"updatedAt" : "2017-07-11T14:22:33.000Z",
"trainStats" : null,
"trainParams" : null,
"status" : "SUCCEEDED",
"queuePosition" : null,
"progress" : 1.0,
"name" : "My Model 2017-07-11 00:00:00",
"modelType" : "image",
"modelId" : "UOHHRLYEH2NGBPRAS64JQLPCNI",
"learningRate" : null,
"failureMsg" : null,
"epochs" : null,
"datasetVersionId" : 3796,
"datasetId" : 1006545,
"createdAt" : "2017-07-11T14:21:05.000Z"
}
We are almost ready!
Predict!
The only thing you have to do is to open the EinsteinVisionDemo demo passing the above Model Id (e.g. /apex/EinsteinVisionDemo?model=UOHHRLYEH2NGBPRAS64JQLPCNI):



The data set used is not the best dataset out there, it's been created with the help of Google and a little of common sense, also the number of images for folder is only 40/50, this means the algorithm does not have enough data to get the job done...but actually it does its job!
"May the Force.com be with you!" [cit. Yodeinstein]

No comments:
Post a Comment